Automating the Search of Relevant Dutch Case Law
An AI layer that reads your case, finds the relevant precedents, and surfaces them in seconds
3 min read
Challenge
Legal professionals spend hours every day manually searching through case law on Rechtspraak.nl to find precedents that support their cases. The government portal is basic, offering little more than simple keyword filters and dense text to read through.
With half a million records in the dataset, this approach does not scale. Relevant rulings get missed and billable hours get lost.
Goal
Turn hours of manual document sifting into a process that takes seconds, by automating how relevant case law is found, read, and summarised across the full Rechtspraak.nl dataset.
Proposed Solution
Users paste a full case text into a simple interface. An LLM reads the text, extracts the key legal concepts and statute references, and uses them to query the Rechtspraak API. The raw results are normalised into clean, consistent data and returned as summarised cases with direct links to the originals.
Plan
- 1Build an entity extraction pipeline where an LLM reads pasted case text and identifies the legal concepts, statute references, and key terms worth searching for
- 2Use those extracted terms to query the Rechtspraak ECLI API, then normalise the XML responses into a consistent JSON structure
- 3Present the resulting cases in a readable summary with direct links back to the original documents
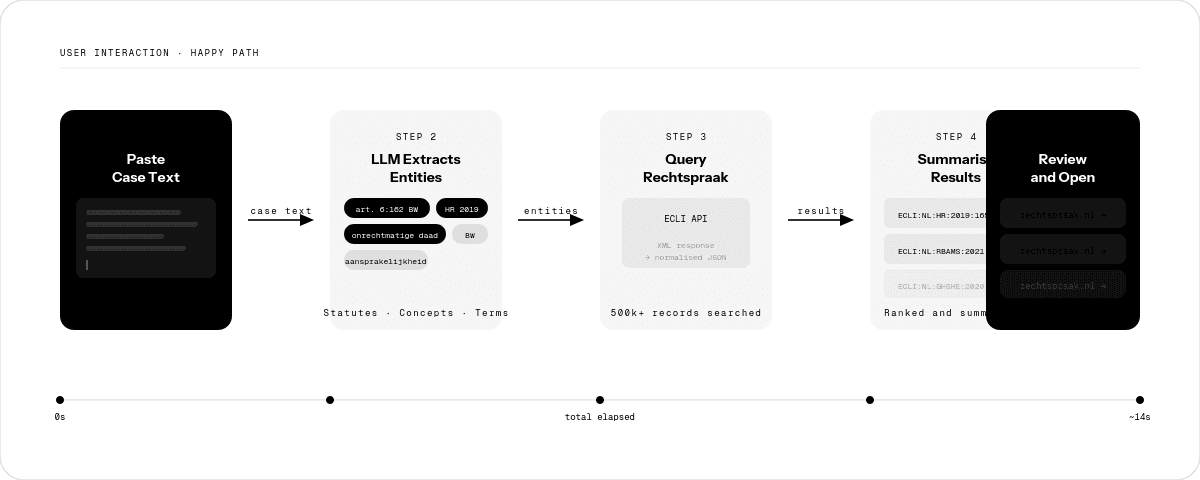
User flow: the professional pastes their case text, the system extracts legal concepts, queries the Rechtspraak ECLI API, normalises the XML responses, and surfaces readable summaries within seconds.
Technical Approach
Programming Languages
Frameworks & Libraries
Infrastructure & Hosting
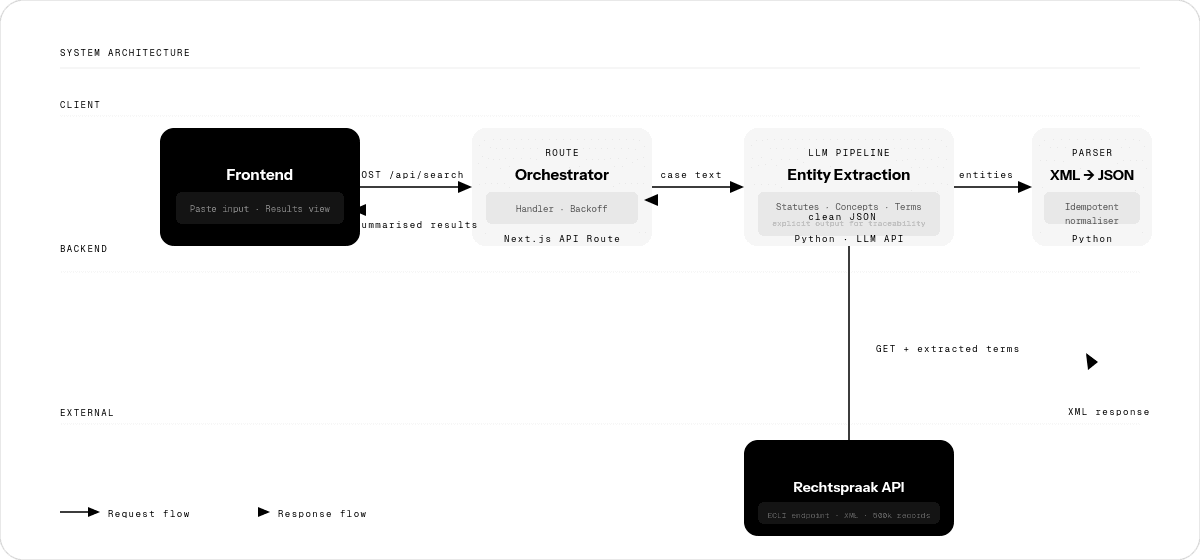
System architecture: the Next.js frontend sends pasted text to an API route where an LLM performs entity extraction, the extracted terms drive queries to the Rechtspraak ECLI API, and an idempotent XML-to-JSON normaliser converts the responses before they are returned to the UI.
Impact
Search time
< 20s
What used to take hours of reading now takes roughly twenty seconds end to end
What I Learned
- –In high stakes professional settings, AI works best when it supports a decision rather than makes one. Start small and keep the human in control.
- –Traceability matters. Showing the entities the LLM extracted makes it clear why certain results appeared.
- –Schema design is as much a product decision as a technical one.
- –Fetching ten documents in one API call and processing them together is often faster and simpler than making ten separate calls.
- –Caching is a necessary next step for any read heavy legal document API.
- –Sometimes a professional spends hours searching and the relevant case law simply does not exist. This solotion quickly answers that too.
Data and schema normalisation pipeline
Writing the XML to JSON normaliser as a pure, idempotent function made it easy to test and rerun whenever the schema needed adjusting.
Challenges & Solutions
Rate limiting on the Rechtspraak API
Sending too many requests in quick succession can cause the API to time out and return errors.
How I tackled it
Added a simple backoff strategy that introduces a short wait between requests.
Reflections
Schema design upfront investment
What I thought
The schema can be cleaned up later once the shape of the data is better understood.
What I learned
Time spent understanding the data before writing any consumers is never wasted. The schema should be treated as a primary design decision, not an afterthought.
Real-world relevance
Concept validation
This project shows that AI can meaningfully reduce the time legal professionals spend on research, turning a slow manual process into something that runs in seconds.
Skill transfer
The normalisation pipeline and field mapping approach used here applies directly to any project that needs to unify data from multiple or inconsistent API sources.
Industry pattern
Enriching a search with AI entity extraction is a pattern that works across domains. Any dataset that is hard to search manually becomes more accessible with this approach.
Want to get in touch?
If this project is relevant to something you’re building, you have any quesions, feedback or interested in having a chat, feel free to reach out.