Health Insurance Policy Q&A
RAG system for querying Dutch health insurance policy documents
3 min read
Challenge
Dutch health insurance policies are long and full of legal text. They have conditional clauses and cross references between sections. To find out if something is covered, you have to search across dozens of pages, read, track exceptions across articles, and understand.
This might take 15 to 30 minutes per question. Which is a slow and tedious process for quick coverage checks or comparing policies. There was no privacy friendly tool that could give instant answers to my personal situation with sources from the actual policy.
Goal
To let people ask natural language questions about Dutch health insurance and get instant personalized answers with citations from the policy documents.
Proposed Solution
Build a RAG pipeline using Zilveren Kruis policy PDFs. Use LangChain, ChromaDB, and a local Ollama LLM. When you ask a question, it finds the most relevant policy sections and answers with precise citations.
Plan
- 1Ingest Zilveren Kruis policy PDFs by breaking them into meaningful chunks and embedding them into ChromaDB.
- 2Build a retrieval pipeline with a prompt that forces answers to come only from the retrieved context so it cannot make up coverage rules.
- 3Show answers with section citations in a simple query interface.
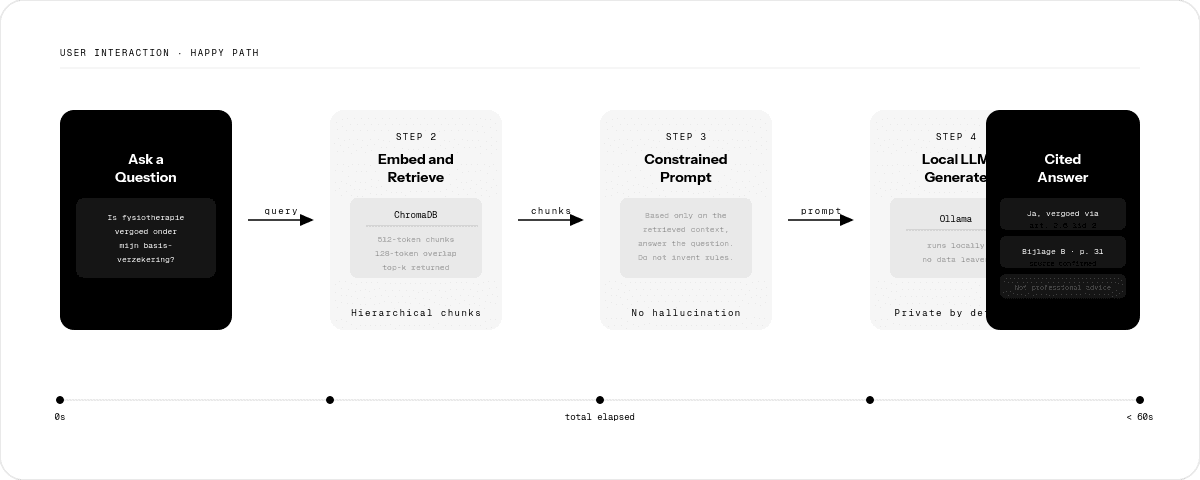
End-to-end user journey: a question enters the system, the retriever finds the most relevant policy chunks, and the LLM returns a grounded answer.
Technical Approach
Programming Languages
Frameworks & Libraries
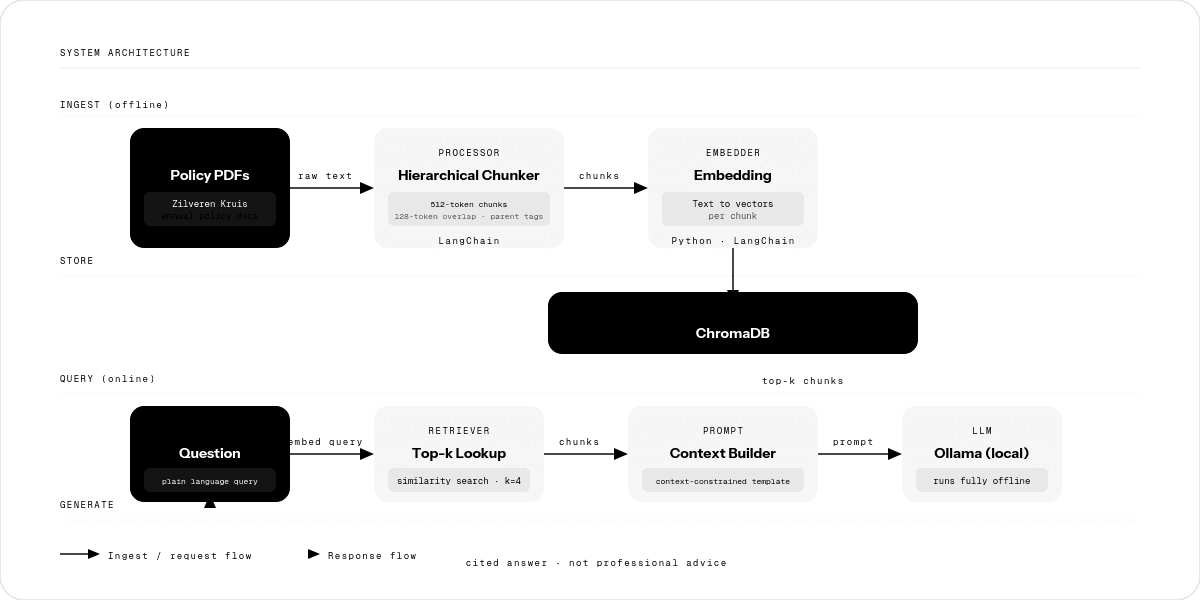
System architecture: PDFs are chunked and embedded into ChromaDB. At query time, the retriever finds the top-k matching chunks, which are added to a context-constrained prompt sent to the local Ollama model.
Impact
Policy question resolution time
<1 minute
compared to 15 to 30 minutes searching manually
What I Learned
- –Policy can be very nuanced and conditional. Small changes in phrasing can change medical coverage.
- –Always cite sources when returning answers. Confidence without proof is dangerous for insurance questions.
Policy language needs careful prompts
Writing prompts like "based only on the retrieved context, answer..." stops the LLM from hallucinating coverage rules not in the document.
Challenges & Solutions
Balancing chunk size for legal documents
Insurance policies have nested conditional clauses that span multiple paragraphs. Small chunks (256 tokens) lost the condition-context relationship, while large chunks (1024+ tokens) mixed multiple unrelated coverage topics, making retrieval noisy and answers imprecise.
How I tackled it
Implementing hierarchical chunking with overlapping windows. Primary chunks are paragraph-sized (512 tokens) with 128-token overlap, and adding metadata tags linking to relevant parent sections. This preserved both local context for precise answers and global context for understanding conditional clauses.
Reflections
Responsibility and disclaimers
What I thought
The system answers accurately enough to trust replies.
What I learned
For any healthcare or legal RAG system, it is important to include a clear disclaimer that answers are not professional advice.
Real-world relevance
Concept validation
This project proves that domain constrained prompts can prevent LLMs from hallucinating in insurance policy RAG systems.
Skill transfer
The hierarchical chunking with overlapping windows approach works for any RAG system dealing with legal, medical, or technical documents that have nested conditions and cross-references.
Industry pattern
This approach can be used to answer policy coverage questions across several domains without losing the conditional logic that determines actual coverage.
Want to get in touch?
If this project is relevant to something you’re building, you have any quesions, feedback or interested in having a chat, feel free to reach out.